Pyxisの開発: Embeddingテーブルルックアップ
前回の記事 でsafetensorsからテンソルデータをf32として読み込めるようになった。今回はそのデータを使った最初の計算として、embeddingテーブルルックアップを実装した。対応するPRは #17 。
embeddingテーブルルックアップとは、入力のトークンIDを浮動小数点のベクトルに変換する処理のこと。LLMの推論パイプラインの入口にあたる。
トークナイザーとBPE
LLMはテキストをそのまま処理するのではなく、まずトークナイザーでトークンIDの列に変換する。トークナイザーはテキストをトークンに分割して、それぞれに整数のIDを振る。たとえばQwen3のトークナイザーだと「tokenization」は
['token', 'ization']
→
[5839, 2022]
のように分割される。「unbelievable」なら
['un', 'belie', 'vable']
→
[359, 31798, 23760]
と3つに分かれる。
分割のアルゴリズムとして広く使われているのがBPE(Byte Pair Encoding)。元々は1994年にPhilip Gageがデータ圧縮のアルゴリズムとして
発表
したもので、2015年にRico Sennrichらが
ニューラル機械翻訳のためのサブワード分割に応用
し、その後GPT-2をはじめとするLLMのトークナイザーにも採用された。最初は1文字ずつ(
a
,
b
,
c
, ...)の辞書から始めて、訓練データ中で隣り合う頻出ペアを繰り返しマージして辞書を大きくしていく。たとえば
t
と
h
のペアが最も多ければ
th
を辞書に追加、次に
th
と
e
が多ければ
the
を追加、という具合に繰り返す。よく出る文字列ほど早くマージされて1トークンになり、珍しい単語はマージが進まず細かいトークンに分割されたまま残る。マージの回数が辞書のサイズを決める。各トークンに0から始まる整数IDが割り当てられる。この辞書に含まれるトークンの総数をvocab_sizeと呼ぶ。
実際のLLMでは、BPEで一から辞書を構築するのではなく、既存の辞書をベースに拡張することもある。 Qwen Technical Report によると、Qwen3ではOpenAIのtiktoken(cl100k_base、約10万トークン)をベースに、中国語の常用漢字・単語や他の言語のトークンを追加し、数字を1桁ずつに分割するようにした結果、トークン数は151643になった。config上のvocab_sizeは151936で、これは151643を128の倍数に切り上げた値。GPUのTensor Coresは行列の次元が64や128の倍数のとき効率が良いので、embeddingテーブルのサイズをそれに合わせている。
Embeddingとは
トークンIDは単なる整数のインデックスで、数値の大小に意味がない(ID 5839がID 5838より何か「大きい」わけではない)。LLMの推論は浮動小数点の行列演算なので、トークンIDをそのまま入力に使うことはできない。各トークンIDを固定長の浮動小数点ベクトルに変換する必要があって、この変換を行うのがembeddingテーブル。
embeddingテーブルは
vocab_size × hidden_dim
の二次元行列で、各行がひとつのトークンに対応するベクトルになっている。hidden_dimはモデル内部で使われるベクトルの次元数で、Qwen3-1.7Bでは2048。vocab_sizeが151936、hidden_dimが2048なら、151936個のトークンそれぞれに2048次元のベクトルが割り当てられている。トークンID
n
の入力に対しては、テーブルのn行目のベクトルをそのまま取り出す。これがembeddingルックアップ。
実装
pub struct Embedding {
weights: Vec<f32>,
vocab_size: usize,
hidden_dim: usize,
}
weights
がembeddingテーブルの本体で、
vocab_size × hidden_dim
個のf32値が一次元のフラット配列として入っている。前回実装した
SafeTensors::tensor_f32()
で読み込んだデータがそのまま入る。
ルックアップはこれだけ。
pub fn lookup(&self, token_id: usize) -> &[f32] {
assert!(token_id < self.vocab_size);
let start = token_id * self.hidden_dim;
let end = start + self.hidden_dim;
&self.weights[start..end]
}
token_id * hidden_dim
で行の先頭位置を計算して、そこから
hidden_dim
個分のスライスを返す。フラット配列を二次元テーブルとして扱っているだけなので、コピーは発生しない。
たとえばvocab_size=3、hidden_dim=4のテーブルなら、weightsは12個のf32値が並んでいて:
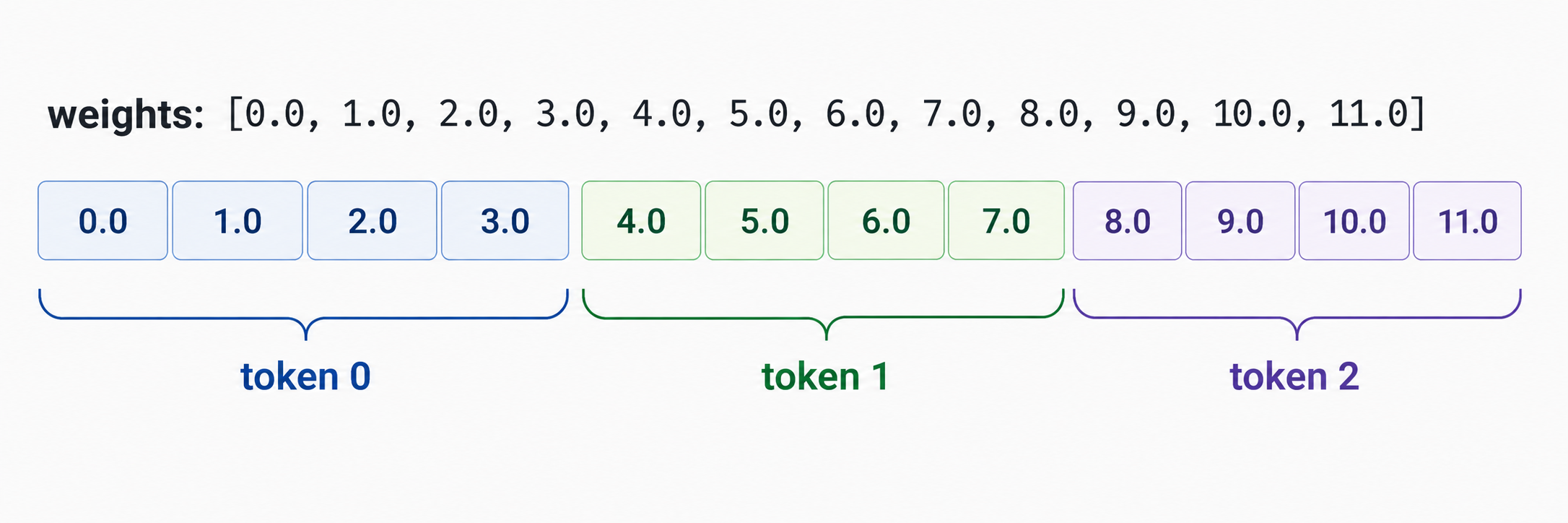
lookup(1)
は
weights[4..8]
、つまり
[4.0, 5.0, 6.0, 7.0]
を返す。
embeddingルックアップ自体は単なる配列のインデックスアクセスで、計算らしい計算はない。ただ、これがトランスフォーマーのパイプライン全体の入口になる。次回はこのベクトルに対して最初に適用されるRMSNormの実装について書く。